Topic Brief: Q-RAG is an ICLR 2026 oral paper that reframes multi-step retrieval-augmented generation by applying We out here tryna use RL to solve a real life cartpole / inverted pendulum situation.
How Reinforcement Learning Systems Fail And What To Do About It -
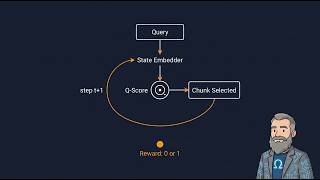
Q-RAG is an ICLR 2026 oral paper that reframes multi-step retrieval-augmented generation by applying We out here tryna use RL to solve a real life cartpole / inverted pendulum situation. In release 4.0, we advanced Spot's locomotion abilities thanks to the power of
Important details found
- Q-RAG is an ICLR 2026 oral paper that reframes multi-step retrieval-augmented generation by applying
- We out here tryna use RL to solve a real life cartpole / inverted pendulum situation.
- In release 4.0, we advanced Spot's locomotion abilities thanks to the power of
Why this topic is useful
This topic is useful when readers need a quick overview first, then want to move into supporting details and related references.
Sponsored
Frequently Asked Questions
Why are related topics included?
Related topics help readers compare nearby references and understand the broader subject.
What is this page about?
This page summarizes How Reinforcement Learning Systems Fail And What To Do About It and connects it with related entries, references, and supporting context.
Is the information always complete?
Not always. Some topics may need verification from official or primary sources.
Supporting Images









Sponsored